
I have used Python extensively over the years with multi-processing code. Be it in a cloud environment inside a Lambda function or even in a terminal running multiple operations simultaneously in different processes.
Since Python introduced the multiprocessing module it has made things easier for people to start using it with multiprocessing. It’s important to understand that this article is not for those looking how to debug multi-threaded Python programs or more specifically pseudo-threaded programs as Python has the GIL limitation.
It is important to note that debugging multiprocessing code can be more difficult than debugging single-process code, as the concurrent nature of the execution can make it harder to understand the flow of control and identify the source of errors. However, with the right tools and techniques, it is possible to effectively debug multiprocessing code in Python.
I’m going to cover some methodologies I’ve used in the past and hopefully you can carry over those tricks in your workflow in order to debug easier issues with your multiprocessing Python applications.
Summary
For those of you that just want to have a quick glance of each debugging methodology that I’m going to talk about I’ve created a table to help you guide make the decision. After that you can jump right into the section or sections that are of interest to you and read more about them.
To make things a bit more clear I put the following criteria for each method as I think those have the biggest weight on which approach to take. Since debugging can have different forms and basically varying degrees of difficulty I wanted to categorize them for you and help you make a decision. The categories I decided on are the following:
- Difficulty: How difficult it is to use a certain methodology
- Programmable: Is the methodology programmable and adaptive so you can put conditions etc.
- Combinable: Can it be combined with other methods easily
- Variation: Are you debugging multiple processes at the same time
- Project size: Is your project big or small
| Difficulty | Programmable | Combinable | Variation | Project Size | |
|---|---|---|---|---|---|
| Print outs | Easy | Yes | Yes | Yes | Not good |
| PDB | Easy | Yes | Yes | Yes | Not good |
| Return Codes | Easy | Yes | Yes | Yes | Good |
| Deadlock defense | Difficult | Yes | Yes | Yes | Good |
| IPC | Difficult | Yes | Yes | Yes | Average |
| RunSnakeRun | Easy | No | No | Yes | Average |
As you can see above my favorite is basically the print outs along with pdb. These should solve most of your problems fairly easily without trying too much to vary them.
I think all methodologies have some advantage if you use them properly and identify your use case properly. The thing to keep away from is trying to combine all of them as it may cause more trouble for you than any good.
1. Use Print Statements
The first and simplest thing you can do is basically start adding print out statements. This method has worked the best for me to debug and identify issues when debugging multiprocessing in python. Even though it’s simple it’s very powerful as you can narrow down where the issue is simply by printing out debug statements.
One handy trick that I like to do here is basically make use of the logger module. So you’d ask me why don’t I just use the print function in Python? The reason is that because I like to control the debugging level and only see it when I am in debug mode and the Python logging module offers this out of the box for you.
Furthermore I can setup different loggers per process, this is very useful especially if you have different names. But even if you didn’t have different names you can easily just append a number after the process so you know what’s going on and make your life easier when reading out the print statements.
import logging
logging.basicConfig(level=logging.DEBUG)
log = logging.getLogger("PROCESS XXX")
log.info("PROCESS XXX running")
The code example above shows how easily you can setup your logger to debug multiprocessing in Python easier and knowing which print statement is from what process.
2. Use PDB
Basically PDB is the standard debugger that Python comes with. It essentially lets you step through your code step by step until you have found your problem. This is particularly useful because instead of adding print outs in every line (I still like to do that) you can see and examine variables as your program runs.
Offcourse this has the problem that if your application is time sensitive it may be a bit hard to do since you need to have speed. For example I had this issue when I was debugging an application that had to do benchmarking and couldn’t be interrupted as it would have delayed all the tests that I was running.
In any case PDB is super simple to use and all you have to do is import and call set_trace where you think you want to start debugging.
import pdb pdb.set_trace()
If you are not certain where you need to start debugging simply set this at the top of your code or at the entry point of the problematic function and you should be able to see the entire process going through.
As a side note here I also prefer to use ipdb which is compatible with the ipython shell and just makes things a bit easier to use since it’s more interactive.
import ipdb ipdb.set_trace()
As shown above the only difference here is that you need to import ipdb instead of pdb but the calling function is still called set_trace. I must note here that ipdb does not come by default and you need to install it using PIP.
The functions of PDB you would be interested in is basically next or shorthand for n which basically moves to the next line of code to be executed. If you feeling more courageous and want to take a deeper dive use the step or s to step inside that function of being executed. In the process you can use the print python function to print variables etc.
Once you are finished use the continue command and your application will just resume execution. Keep in mind if you are lost at any time inside your debugging there’s a handy where which shows you a stack trace of where you are at in the Python code. I generally tend to use that when I am debugging for prolonged periods of time.
3. Check For Return Codes
The most obvious one that a lot of people miss when debugging multiprocessing in Python is to check for the result of your code. Yes this is right make sure your code outputs the right answer in all cases across all the processes being executed. A good example would be if you are expecting for example an integer from one of your multi-processes executing and it returns a string or doesn’t return at all (has an exception). In that case you obviously have a problem and the easiest way to do this is using a Pool that’s available in the multiprocessing module.
from multiprocessing import Pool
def some_function(arg):
return arg*2
with Pool(2) as p:
for result in p.imap(some_function, range(5)):
print(result)
The example above basically allocates a pool of processes to be executed and prints out their result (what they return). This is more of a Pythonic way of checking the output rather than going into a shell and seeing the return code of it. If you want to enhance this even further you can use the logger module instead of print to distinguish between all the different processes.
This method has worked very well for me to debug multiprocessing in Python as it’s a combination of two of the methods I use.
4. Play Defense Against Deadlocks

From the multiprocessing module you can use locks or semaphores to protect shared resources and avoid race conditions. The code below lets you use a lock creation.
from multiprocessing import Lock
lock = Lock()
def some_function():
lock.acquire()
try:
# code that accesses shared resources
finally:
lock.release()
Basically locks are vital when you are working with multiprocessing debug in Python as they influence how your data assets are shared and accessed across all the processes you have.
The natural defense in this case is to basically protect them and ensure every process plays nice in this and doesn’t hold up a resource from other processes. If that happens then you will have a deadlock and you will just be sitting there with processes never ending and sometimes falling into endless loops that can be very CPU intensive.
So make sure you protect against these cases by using locking as demonstrated above.
5. Use Inter Process Communication
Using multiprocessing Event class, you can use events to communicate between process and synchronize their execution. Basically an event is a way of signaling a change is happening in one of your processes. This is particularly useful when debugging multiprocessing in Python as you have a way of communicating.
Now that you have this asynchronous way of communicating you can extend the logic programmatically and signal certain things based on your suspicions of where the problem may be in your code. So debugging them with a narrowing out approach you can slowly squeeze the scenarios and come to the root cause of the problem.
from multiprocessing import Event
stop_event = Event()
def test_func():
while not stop_event.is_set():
# run some code here
# To stop the execution
stop_event.set()
The code above basically checks the stop event which was created using the multiprocessing event in a while conditional loop inside a function we suspect there’s a problem. You can do the same thing in other places until you find the issue. In some cases and I do frequently I acquire more than one event object to cover more use-cases when I’m not sure what’s happening.
This methodology requires a bit of drilling and trial and error but it works quite effectively on letting you identify what might be going on. It has the advantage over the other methodologies such as PDB and print outs that if your application does a lot of things it will be hard to shift through all the output. With events you have an elegant way of narrowing this using Python conditions such as if statements or other things based on data logic.
Always remember to use locks like we discussed earlier if you are checking specific data otherwise you may end up with a deadlock.
This approach is good to debug multiprocess in Python when dealing with a lot of processes that are very verbose, for the other approaches I prefer to use the print out method alongside with PDB to keep things simple.
6. Use RunSnakeRun
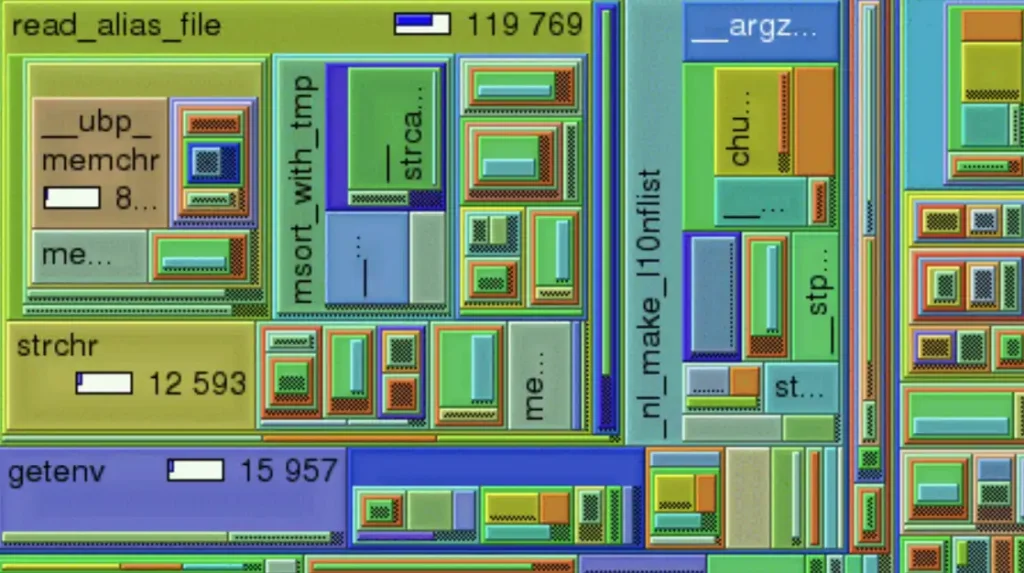
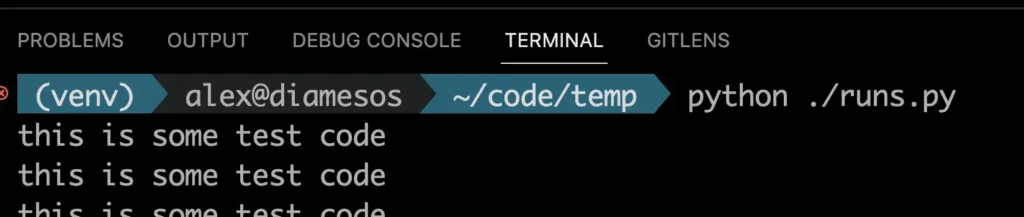
Using runsnakerun you can basically profile each Python process as you would normally do to identify any issues with the code. To do this we will implement a simple Python script that basically runs a loop and sleeps for a small period of time.
import time
def test_code():
print('this is some test code')
time.sleep(0.5)
def main():
for i in range(20):
test_code()
if __name__ == "__main__":
main()
Now that we have this saved we will go ahead and execute it but instead of running it via the usual Python executable we will wrap it inside the runsnakerun executable.
It must be noted here that you need to install it in your system using pip as follows:
$ pip install runsnakerun # I had to install on MAC wxpython too to get it to work $ pip install wxpython==4.0.0
The extra command was to resolve an exception my Mac was having initially with the following error:
Traceback (most recent call last):
File "/Users/alex/code/temp/venv/lib/python3.9/site-packages/runsnakerun/runsnake.py", line 836, in OnInit
frame = MainFrame(config_parser=load_config())
File "/Users/alex/code/temp/venv/lib/python3.9/site-packages/runsnakerun/runsnake.py", line 216, in __init__
self.CreateControls(config_parser)
File "/Users/alex/code/temp/venv/lib/python3.9/site-packages/runsnakerun/runsnake.py", line 268, in CreateControls
self.rightSplitter.SetSashSize(10)
AttributeError: 'SplitterWindow' object has no attribute 'SetSashSize'
This basically resolved my issue and I was able to run it to see how each Python intermodule was taking up computing power broken down by function and libraries used behind the scenes. Now in order to identify this in debugging multiprocessing Python you need to perform the same operation in all of your processes if they are following a different flow based on conditions.
Once you do that you should be able to visualize identify the error in your code.
7. Use Common Sense
Alright this isn’t really a methodology but since it’s so important and has helped me resolve problems in the past I want to list it here and use it as you wish. Basically I’m stating the obvious but common sense can go out of the window if you get dragged too much in things that don’t matter.
Let me give you an example once I was debugging a case where my network was timing out. This was happening specifically from one server but at that time I wasn’t sure about it. So I dove right into it and started debugging the hell out of it only to find out that there was a connectivity issue.
Now if I had taken a step back and looked at the bigger picture that my code was working fine and without any code changes it stopped working I would have probably done something more pr0-active to begin with such as checking network connectivity, cables, ISP but I didn’t. The result? I spent hours debugging something that was external to our application code.
For the record for those that are curious it ended up being a routing issue with our hosting provider at the time so specific connections had problem completing and were ending abruptly causing the entire function to fail. What I am trying to say here please use your common sense before you take a deep dive to any problem, try to narrow out external problems or something specific to a setup. Look if your code was changed and if it hasn’t start getting suspicious of what could have broken it.
I know this comes with experience and it isn’t something you can ingrain into someone’s brain but if you try you will eventually get better at it and be able to resolve sometimes complex issues that don’t even require code changes.
Over the 25 years that I’ve been into software engineering I have become so good at it (not trying to brag just stating a fact) that people come to me to diagnose things that entire teams have not been able to find. I think what helps me hear the most and I want to pass on this to you before I drop off in this writing is that I have a spherical knowledge of how computers work. I understand everything from the lowest layer to the highest from networking to hardware and coding.
Before you accuse me for bragging I’m going to pause here and leave to the fact that is the same no matter what your experience is, use common sense!