
Introduction
We are going to discuss on How to Auto Increment in DynamoDB simple and easy to follow guide.
DynamoDB works differently with increments from traditional SQL
I break it down into three main sections:
- Go over the limitations of DynamoDB
- The reason why DynamoDB is doing things in a certain way
- How you can deal with auto-incrementing
I have been working in the Software industry for over 23 years now and I have been a software architect, manager, developer and engineer. I am a machine learning and crypto enthusiast with emphasis in security. I have experience in various industries such as entertainment, broadcasting, healthcare, security, education, retail and finance.
If you would like to understand the API better I have written an article on it which you can find here:
Boto3 DynamoDB query, scan, get, put, delete, update items
Does DynamoDB Support Auto Generated ID
The short answer is that DynamoDB does not support autogenerated IDs. However there’s a good reason behind it and this is that it impacts the scalability of their implementation and goes against the NoSQL principles. Having said that if you are trying to on-board a SQL traditional database into your NoSQL you have two options on how you can deal with that limitation.
I will provide below 3 work-arounds that will help you accomplish this task.
1. The Easy Solution – Use A Library For AutoID Generation
The easy way to solve the problem for generating automatically IDs for DynamoDB is with the use of a helper library. Based on what language you are using you can find implementations and incorporate them to your code. The difference here is that where you would usually issue a put item function call with the data you want to insert you will be invoking the library function to insert the data for you.
You may ask how does the library work?
This is a perfectly valid reason, the way these libraries work all rely on one principle and this is finding the last inserted record retrieving the ID from it and then simply incrementing it by one when you are inserting the new item in the database. While this method can make your life perfectly easy and can work in some cases as you can understand it comes at a performance impact for the following reasons:
- You are now performing two database queries which will obviously double the amount of database work you’d be doing
- One to find the last ID
- One to insert the data
- You have to keep track of an identifier when in reality you don’t need too
- You need to ensure your transactions are atomic by using a Queue to insert your data
The last pointer seems rare but consider the following scenario:
User 1 wants to insert a record in your database, so they fetch the last identifier let’s assume this is number 3.
User 2 wants to do the same thing, while the first fetch is running the second one is also running (insert hasn’t completed yet) so User 2 gets the identifier as 3 too.
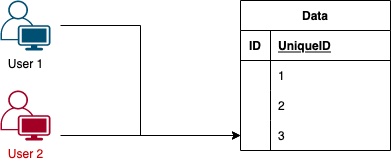
If the above considerations are taking into place then you can abstract the logic and have it happen automatically.
2. A Better Workaround – Use a Different Unique ID
This method is fairly simple but it would require you to do some extra work. Instead of using an identifier you can use a unique UUID number. The UUID number can be composed by any random pseudo or not generated number and then replace the ID. The advantage of this method is that you will be guaranteed uniqueness and you will be able to do this in only one query.
- The disadvantage of the above method however is that you cannot reliably always get a unique number unless you are using a true source of randomness, especially if you are having multiple Lamba’s doing the update and timing could be an issue. In order to improve this I have written an article on generating true random numbers which you can find below and can help you remediate this problem. How To Generate Truly Randomness In Python. So the updated table will now have a column called ID but instead of using incremental numbers like 1,2,3,4.. you’d have a list of UUIDs.
- Another caveat of this approach is that you need to spend more CPU time generating the unique ID besides guaranteeing it doesn’t already exist in your database.
- On top of that a single numeric takes a lot of disk space and memory when loading the result than a UUID so you will have an impact on your network communications as well as you are getting more data. This has a compound effect the more records you have when making a pull of data. As you can see from the graph below this is a linear increasing graph based on the number of records you are trying to pull so it’s not efficient.

- Debugging will be harder, UUID’s. Numbers are much easier to find a record that’s a simple numeric value when looking up things than it is for a UUID.
- Indexing and performance on queries is also affected. It will take longer to create a hash for a UUID than a simple number, also your indexes will be longer and more space consuming even if they are abstracted by the DyanmoDB layer.
- One thing to note is that if your tables have any foreign key mapping for integers then when you first initialize your database you will need to do an extra step remapping this data to the UUID instead of the number.
3. The Right Way – Reconstruct Your Tables
The best approach by far is to reconstruct your table layout specifically to be optimized for DynamoDB. But what does that entail you may ask. I have broken this up in some sections to discuss it briefly but will not go into too much detail since it’s beyond the scope of this article. If you’d like to me to do a more detailed approach on it please leave me a comment below and I will.
The added benefit to going holistic and reconstructing your tables is that you will have a cleaner and more easier schema. Essentially the dependencies will be evident and your queries will also be faster since you can optimize for your sort and partition key.
Forget About AutoIncrementing IDs – Use Proper Partition And Sort Keys
DynamoDB simply does not have as a concept an auto-incrementing ID as it’s basically a key-value database. This means you need to stop trying to apply this logic here as it will not carry over and things are done in a different way. Instead think in terms of Sorting and Partitioning.
The Sorting key is simply that a key that helps you sort the data a good example of that would be a date.
The partitioning key similarly helps you partition your data so it’s easier to access, it’s very easy to confuse this with a primary key in traditional SQL as they share a lot of similarities but they do have differences which you can read more about here.
Think In Terms Of Collections Instead Of Tables
In traditional SQL you are probably thinking in terms of tables and how to chain them together using foreign keys. DynamoDB works in terms of collections where you can optimize your data in such a way where everything is part of the object as an attribute identifier.
Lets look at an example below of a Media Store.
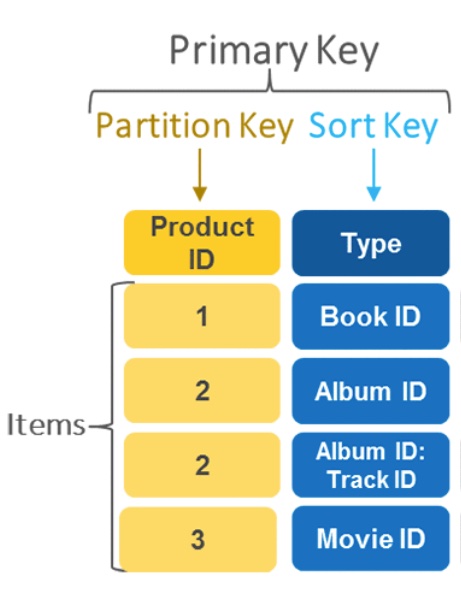
As you can see above these are simply attributes to a specific collection you have, in the example above this is a media store that has books, albums and books. The selection in this case is pretty straight forward and very similar to a SQL primary key, the product ID. In some cases this can get more complicated and you may want to partition your data in a different way such as selecting a composite of various attributes together to uniquely identify and partition your data.
Why Is Auto Increment Bad For DynamoDB
As mentioned earlier auto increment is not a concept that carries over to a key/value database like DynamoDB. Traditionally NoSQL databases work without identifiers and such. Instead they use partition and sort keys which are similar but the concept of the foreign key does not work in such a way. I mentioned three ways of implementing the above which you can find here.

How to Make a UUID in DynamoDB
The process on generating a unique UUID relies entirely based on the randomness you can select as your seeding value. Typically people use a date time but this could problematic when you have concurrency and multiple lambdas writing into the same database store. I have detailed explained how to do this earlier in this article which you can find here.
How to Use Auto Increment for Primary Key ID in DynamoDB
You can’t really use auto incrementing for a primary key in DynamoDB simply because DynamoDB does not have any support for primary keys. The alternatives which I described earlier are based on three work-arounds which provide a complete solution to this problem. In reality if you want to stay consistent with the idea of a primary key you need to use a library that basically makes two calls instead of one. More can be found here.
Does DynamoDB Primary Key Need to Be Unique
As mentioned earlier DynamoDB does not have primary keys instead it uses partition keys which are different. It does need them to be unique and specific to what you are looking for as they are used for the collections. Your partition key can be a composite of a date, uuid or other identifier you choose it to be. We must note here that the primary key is also referred to as the partition key in the database or also known as hashing key.
Can You Update Primary Key in DynamoDB
You cannot directly update the partition key in DynamoDB. Once a record is inserted in the database with a particular partition key it has to remain as is.
However you can accomplish this with the method detailed below:
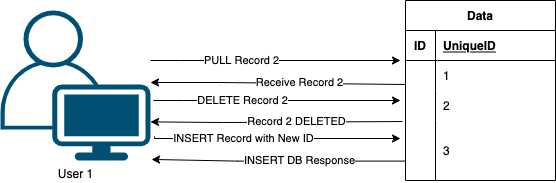
- Retrieve the record you want to update the partition key for (also known in Dynamo as the partition key)
- Delete the record that has the partition key you want to update
- Re-Insert the record into the database using the data you pulled previously but replacing the partition key with the one you want to use
As you can see this method works well it involves 3 calls instead of 1 but it gets the job done for you.
Conclusion
If you found How to Auto Increment in DynamoDB useful and you think it may have helped you please drop me a cheer below I would appreciate it.
If you have any questions, comments please post them below I check periodically and try to answer them in the priority they come in. Also if you have any corrections please do let me know and I’ll update the article with new updates or mistakes I did.
One thing that I want to add here is that if you are looking for a better generic solution it’s always best to go by what the database supports natively. Since the architecture and design team of AWS does not think it’s a fit there’s probably a lot of good reasons for it so don’t go against that or you will eventually hit a roadblock. If you must then follow what we discussed earlier.
Which work-around do you use for your auto-incrementing in DynamoDB?
I personally like to use a dynamically generated UUID and repurpose my tables to refer to that.
If you would like to learn more about AWS Databases I have written many articles which you can check below: