
Introduction

We will go over How To Extract Human Names Using Python NLTK.
Did you know that NLTK can help you identify named entities such as names and surnames?
I will break this review in the following sections:
- What is NLTK and how it can help you find names in text
- Go over example code step by step
- Test it and see how it works with real examples
I have used this successfully in various projects and it works very well.
We will go point by point on getting you up and running in less than 5mins of work.
This is a complete guide and should cover all your questions on How To Extract Human Names Using Python NLTK.
All code associated with this can be found in the GitHub page here.
Why Is NLTK Useful For Named Entity Recognition
There’s several reasons why you may want to use NLTK for your named entity recognition. I will try to list them below and see if this matches your use-case and if it may be helpful for your project. Having said that if you came to this article I’m sure you have your own reasons or just curious. If I miss something in this list please send it to me in the comments below I would be curious to know.
- It’s a complete framework that has all the code written for you to detect names in text using Python
- It’s supported in Python which your code base may be already written in
- It has trained sample data so you may not have to do your own training
- It’s a mature project and has a good track record
- The success of named entity detection is very good especially if you do good tokenization of your text
- It lets you override some named entities to different things, for example consider you have a name but it represents an organization/company instead. NLTK lets you do this effortlessly and update your code and models.
If you find yourself being in one of the above categories then please read on as I will try to simplify the process of installation and using it.
Setting Up Environment For NLTK
We will start by setting up your environment on how to run it with all the package dependencies. If you have already done this you can either skim through this section or simply skip over and go straight to the implementation part of things.
Creating A Virtual Environment For NLTK
The first thing we need to be doing is setting up a virtual environment so it doesn’t conflict with our main system python packages. This will keep things clean and will allow you to quickly deploy it in containers and other installations later on if you need too.
We will be creating a virtual environment using the virtualenv command but you can also use condo to create this. All code examples can be found in the Github repo here and will be using Python 3.
$ virtualenv venv created virtual environment CPython3.9.10.final.0-64 in 200ms creator CPython3Posix(dest=/Users/alex/code/unbiased/python-extract-human-names-nltk/venv, clear=False, no_vcs_ignore=False, global=False) seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/Users/alex/Library/Application Support/virtualenv) added seed packages: pip==22.0.4, setuptools==60.9.3, wheel==0.37.1 activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator $ source venv/bin/activate
Once the virtual environment is created and activated we can proceed into the next step which is starting to add the necessary packages for NLTK to work.
Installing Python Packages For NLTK
To simplify the process I included a requirements file in the Github repo that allows you to simply use it for the installation process.
The script I have written that will install everything and get you started is the following:
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('maxent_ne_chunker')
nltk.download('words')
As you can see this installs the following dependencies which are the minimum you need to get NER going:
- punkt: A punctuation helper library
- averaged_perceptron_tagger: This is used for tagging your words in a sentence using a perceptron for NLP
- maxent_ne_chunker: This will chunk up the data from the sentence so it can parse it
- words: This is a simple word list which is used as a basis for the named entity recognition, you can extend this if you would like too
The next step is to go ahead and perform the install/download of the dependencies by running the script.
$ python ./install_nltk_punkt.py [nltk_data] Downloading package punkt to /Users/user/nltk_data... [nltk_data] Package punkt is already up-to-date! [nltk_data] Downloading package averaged_perceptron_tagger to [nltk_data] /Users/user/nltk_data... [nltk_data] Package averaged_perceptron_tagger is already up-to- [nltk_data] date! [nltk_data] Downloading package maxent_ne_chunker to [nltk_data] /Users/user/nltk_data... [nltk_data] Package maxent_ne_chunker is already up-to-date! [nltk_data] Downloading package words to /Users/user/nltk_data... [nltk_data] Package words is already up-to-date!
In my case everything already pre-existed on my system so it just verified that they were up to date. In your case if you are doing this for the first time it may download the dependencies first.
The main package defined above is NLTK and this will essentially pull all the dependencies along it and create a big Python dependency list. If you are interested in that you can use the following pip command to save the versioning of the packages and ensure compatibility with future versions.
$ pip freeze > requirements-deps.txt
Essentially this freeze lets you capture the versions of your dependencies too in case those get updated and do not stay backwards compatible with your code. I always make a backup of those every time I start a project even if I don’t end up using them as a good practise so I can always go back to what I need without having to port code to newer versions.
Language Packs For NER NLTK
As mentioned earlier the words package basically contains everything in English words that we can use in the NLTK library.
This means it’s already pre-trained to use this data and you do not need to do anything to extend it unless you want to use a different language.
If you were to lets say use Spanish as your main language in NLTK for detection you will need to replace the pre-trained records made for the words NLTK package. Once this is done in your code NLTK will use the updated packaging to detect Spanish words and be able to perform NER analysis on Spanish names and surnames.
Find Names In Text Using NLTK
Architecture Of NLTK NER
Before proceeding into demonstrating the code I’d like to run you through the steps involved in any NLP and particularly the NLTK NER Python module on how it works from top level.
To do this I will use the aid of the diagram below and later explain this in detail in our code.
It’s important to understand at a high level how NLP works
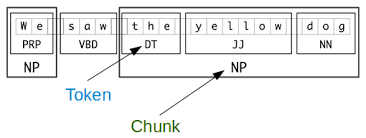
Basically a token is a simple word in the simplest term of it. This is part of something bigger called a Chunk which can contain more words as shown above. So essentially you can think of a Chunk of a superset of a Token. Or simpler a chunk is composed of a set of Tokens.
But are tokens just words? Well not exactly basically a token is a word but it carries another aspect to it which is a tag. A tag is essentially an identifier of what the word could be. So for example lets take a look at the screenshot above.
The part we are looking for is basically the token: Dog as you can see below it, it has something saying NN. This is shorthand for a noun.
Hopefully things are more clear now on how an NLP works. The process is three staged that creates those chunks that consist of tokens and each of them has a tag associated to it on what it could be.
Now that we got this out of the way lets see what NER is and how this expands upon the existing process of NLP.
Basically an NER takes those tags and starts putting them in a list to see if they are a named entity. And what is a named entity you may ask?
A good example of a named entity is basically a PERSON. So if that token had a name lets say in there Alex Smith, that would have a named entity type of PERSON.
This is how we identify names using NLP. It was important for you to understand how things work behind the scenes in order to be able to know what’s happening in your code. So let’s get into a proper coding example and see how this translates and how we identify names in text using Python and NLTK.
Code To Extract Human Names In Python NLTK
Now that we have our environment setup we can start talking about writing the code on how to extract the names from text using Python NLTK. As a first example we will examine how to do this using some English text and the training set we previously downloaded words package of NLTK.
We will use an example of a paragraph that simply contains two names to see if our code will be able to identify them and yield results of the named entity recognition.
The sample code below will achieve this for us.
import nltk
from nltk import ne_chunk, pos_tag, word_tokenize
from nltk.tree import Tree
text = '''
This is a sample text that contains the name Alex Smith who is one of the developers of this project.
You can also find the surname Jones here.
'''
nltk_results = ne_chunk(pos_tag(word_tokenize(text)))
for nltk_result in nltk_results:
if type(nltk_result) == Tree:
name = ''
for nltk_result_leaf in nltk_result.leaves():
name += nltk_result_leaf[0] + ' '
print ('Type: ', nltk_result.label(), 'Name: ', name)
The things we need to note in the code above are:
- We load the language set pack at the very top, this will be used as our NLTK NLP (Natural Language Processing) engine.
- Then we have some sample text this can be coming from any source you want, just save it as a string.
- Then we need to do some grammatical stuff using the NLTK engine in the order specified below:
- Word tokenization
- Tagging the tokens
- Chunking the end result
- Now that we have the chunks of the results we process them individually until we find one that’s of type Tree which means there’s some NER data in that field.
- We expand and explore each of the leaves which are part of the master node and just print out what we find such as:
- Label
- Name
Testing Code To Extract Human Names In Python NLTK
Now that we covered how the code works let’s go ahead and execute this and see what it will output for us in terms of identifying names in the long string we provided.
$ python ./find_human_names_text_english.py Type: PERSON Name: Alex Smith Type: PERSON Name: Jones
As it can be seen above the code found two instances:
- Alex Smith which is of type PERSON in this case it just means it’s a name
- Jones which is just a surname and again is of type PERSON
This concludes finding all the names in our string. Do note that sometimes NLTK may mislabel a name in which case it means you need to train it a bit on your own by improving the words dictionary it uses.
Since training is beyond the scope of this article and may be a topic of it’s own I am going to link to the official page which has some example code and may be helpful for you to train your own models. You can find more information here.
Note that the types such as PERSON and any other entity identifier can change between versions. For now that tag PERSON is backwards compatible with all NLTK versions and it’s guaranteed to work.
If you want to debug this on your own and see what has changed you can do a dump of all the labels in your tree using the following code:
nltk_result.label()
So you simply print them all out and decide for your self what it could be.
How To Remove Names From Text Python
Now that we have a way to identify our names in the text we can take this a step further and using Python we can also remove the names from the text. To do this we can make use of the function called replace. A sample snipet to implement this is shown below:
text.replace('Alex Smith', ' ')
This works as follows:
- We store the variable of the name we identified in this case I put the name explicitly to Alex Smith and call replace on the text attribute
- We next simple replace this with an empty space so the text doesn’t look weird
- In the scenario above if we were to implement this in our loop we would be replacing Alex Smith with the variable name so the final code will be something like:
text.replace(name, ' ')
Do note if you want to conditionally replace specific names in text with Python then you need to add a condition to the names you consider should be replaced, otherwise the for loop we implemented will replace all names in text found with an empty space using that Python code.
Extract Names From File Using NLTK
Extracting names from a file using Python is very similar to what we did before. Since Python provides simple functionality to read a file we simply need to open the file and save the output to a string.
Once the output is saved to a string we can use the code we demonstrated earlier and reference that string instead of the sample that we used.
text = open('filename.txt', 'r').read()
In the example above we simply read the contents of a file called filename.txt and save it into the same variable called text that we can later pass on to our NLTK engine to do the NER extraction as discussed above.
Extract Names From Word Document Using NLTK
To do this we will be using the same core code that we had used previously instead to extract the blob of text which we will be analyzing we will make use of a helper library that understands and knows how to parse word documents for Python.
So the task at hand like in the previous section is to get the text in a buffer where we can process it via our NLTK engine to find human identifiable names in the text.
The library we will be leveraging here is called docx2txt. Basically this is a python package that you can install using PIP as shown below:
$ pip install docx2txt Collecting docx2txt Downloading docx2txt-0.8.tar.gz (2.8 kB) Preparing metadata (setup.py) ... done Building wheels for collected packages: docx2txt Building wheel for docx2txt (setup.py) ... done Created wheel for docx2txt: filename=docx2txt-0.8-py3-none-any.whl size=3960 sha256=0daae163f075f0ea868f11a430b89db81c9f2ea0281e317b499afca8a24978dc Stored in directory: /Users/alex/Library/Caches/pip/wheels/40/75/01/e6c444034338bde9c7947d3467807f889123465c2371e77418 Successfully built docx2txt Installing collected packages: docx2txt Successfully installed docx2txt-0.8
Now that we have the docx2txt library installed we can go ahead and use the Python code shown below to extract the text so it can be used by the NLTK engine to extract names.
import docx2txt
text = docx2txt.process("Document With Names.docx")
We successfully loaded using the doc2txt function called process that returns a string buffer to be used in the rest of our code. Since our old code was already processing this text we can re-use it and just continue execution using the new text we have.
This new text can now be processed and yield the human names identified in the word document using NLTK.
In 2023 NLTK has improved greatly at detecting human names in text. The proof for this is that training sets for the named entity recognition have been updated resulting into more accurate and higher chances of finding a name if it exists on the text you are examining.
NLTK Named Entity Recognition
What we demonstrated above shows how NLTK does named entity recognition. However there’s more to it lets do a deeper dive into understanding what’s happening besides the scene when we use NLTK to do named entity recognition.
NLTK maintains internally what is called an NLTK tree that has a datatype of: nltk.tree.Tree. This is nothing but a Python tree structure which basically contains all the information it has created from the parsing functions that were used along with the tokenization. More specifically each leaf of this tree is basically a word it found in the text you are looking along with a type it has allocated to it. For this I have created a diagram to try and give you a visual representation of how this may look:
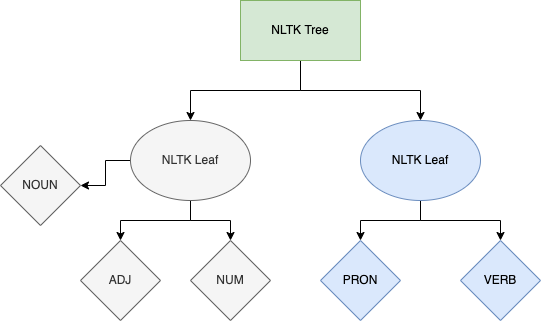
NLTK Entity Extraction
By traversing the tree above we can basically perform of what’s called entity extraction. Since NLTK offers this in an easy to use iterator we can perform this operation directly in the class object we identified earlier as the Python NLTK Tree which has the entities.
As you can see above the tree leaves are broken up in specific tags. You can find a whole list of those referenced here. What this really means is that NLTK took care for you for the named entity recognition. So while traversing the tree you can basically identify what you need. In our previous cases we went a step further and identified names but this can essentially span out for anything else. As a closing note I put that here in case you want to extend the code to do more things. If you are interested to learn more on that please drop me a line below and I’ll make sure to come and make a new article for you.
Conclusion
We were able to successfully go over How To Extract Human Names Using Python NLTK, hopefully I answered any questions you may have had and helped you get started on your Python name finding project.
Since the introduction of new technologies such as Chat GPT and OpenAI based products the named entity recognition has increased in popularity a lot. We are seeing different models that may be worth a try in the near future. I suspect both NLTK and other frameworks will be due for a modernization/overhaul.
If you found this useful and you think it may have helped you please drop me a cheer below I would appreciate it.
If you have any questions, comments please post them below or send me a note on my twitter. I check periodically and try to answer them in the priority they come in. Also if you have any corrections please do let me know and I’ll update the article with new updates or mistakes I did.
Which is your favorite way of finding names in big data?
I personally use a combinations of libraries such as spaCy and NLTK. In this guide I covered How To Extract Human Names Using Python NLTK using NLTK in a guide listed below I also cover how to do this using spaCy.
If you would like to visit the official NLTK documentation here.
Do note that you can use both spaCy and NLTK synergistically to improve the results of your named entity recognition in Python code.
If you would like to find more Python related articles please check the links below: