Introduction
Today we will discuss on everything you need to know about How to use Boto3 Pagination and Collections in simple and easy to follow guide.
Would you like to know which is better Pagination or Collections for your project?
This is your ultimate source to quickly understand and get hands on, on how to implement Boto3 Pagination and Collection guide and why it’s useful for your project.
More specifically we will discuss:
- What are Paginators and how to use them
- What are Collections and how to use them
- The differences between the two
All the code and examples that will be provided below can be found in my git repo here.
I have been working in the Software industry for over 23 years now and I have been a software architect, manager, developer and engineer. I am a machine learning and crypto enthusiast with emphasis in security. I have experience in various industries such as entertainment, broadcasting, healthcare, security, education, retail and finance.
How to install Boto3 to connect to use Pagination and Collections
We are going to begin on setting up our environment in particular installing any dependencies and packages necessary. I assume you already have Python 3 installed and running in your system. If you haven’t you can check the official website of Python to get that installed before proceeding forward. Furthermore I’m assuming you already have access to an AWS EC2 account and own an SDK key. If you do not you can sign up for free with Amazon here to get started. I’m also making the assumption you have the Python Package manager pip. If you haven’t you can look into this guide to learn more about installing it.
Now that we have the basic requirements out of the way we can dive in and start setting up the system. Also I want to note that all of the code you will find in this guide can be found in github here.
How to Create a Python Virtual Environment for Boto3 Pagination and Collections
- First install the virtual env using the python command: ‘pip install virtualenv’
- Then create a new virtual environment
- Finally you need to activate your virtual environment so we can start installing packages, please see below
main alex@DYNAMH ~/code/unbiased-coder/python-boto3-pagination-collections > virtualenv env
created virtual environment CPython3.8.6.final.0-64 in 3773ms
creator CPython3Posix(dest=/home/alex/code/unbiased-coder/python-boto3-ec2-guide/env, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/home/alex/.local/share/virtualenv)
added seed packages: pip==21.2.4, setuptools==57.4.0, wheel==0.37.0
activators BashActivator,CShellActivator,FishActivator,PowerShellActivator,PythonActivator
main alex@DYNAMH ~/code/unbiased-coder/python-boto3-pagination-collections > source env/bin/activateHow to Install pip dependencies for Boto3 Pagination and Collections
Next we need to go ahead and install the Python dependencies to be able to use the boto3 library. You can do this by running the pip tool as shown below. Keep in mind make sure your virtual environment is activated before you run this step. If you wish to use it without having a virtual environment which I do not recommend you can go ahead and simply install it globally in your user account.
main (env) alex@DYNAMH ~/code/unbiased-coder/python-boto3-pagination-collections > pip install boto3 python-dotenv
Collecting boto3
Downloading boto3-1.18.46-py3-none-any.whl (131 kB)
|████████████████████████████████| 131 kB 1.1 MB/s
Collecting s3transfer<0.6.0,>=0.5.0
Downloading s3transfer-0.5.0-py3-none-any.whl (79 kB)
|████████████████████████████████| 79 kB 2.8 MB/s
Collecting botocore<1.22.0,>=1.21.46
Downloading botocore-1.21.46.tar.gz (8.2 MB)
|████████████████████████████████| 8.2 MB 11.5 MB/s
Collecting jmespath<1.0.0,>=0.7.1
Downloading jmespath-0.10.0-py2.py3-none-any.whl (24 kB)
Collecting python-dateutil<3.0.0,>=2.1
Downloading python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
|████████████████████████████████| 247 kB 10.1 MB/s
Collecting urllib3<1.27,>=1.25.4
Downloading urllib3-1.26.7-py2.py3-none-any.whl (138 kB)
|████████████████████████████████| 138 kB 9.9 MB/s
Collecting six>=1.5
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Building wheels for collected packages: botocore
Building wheel for botocore (setup.py) ... done
Created wheel for botocore: filename=botocore-1.21.46-py3-none-any.whl size=7933638 sha256=ee2d8a7f5bd91a7d2711b529706902a4a2a8fba97e69493757a8d1d461296d69
Stored in directory: /home/alex/.cache/pip/wheels/db/2a/b6/37624d07c0d7572bff3d08bd4bfd2c94b121f693278cd1ae77
Successfully built botocore
Collecting python-dotenv
Downloading python_dotenv-0.19.0-py2.py3-none-any.whl (17 kB)
Installing collected packages: six, urllib3, python-dateutil, jmespath, botocore, s3transfer, boto3, python-dotenv
Successfully installed boto3-1.18.46 botocore-1.21.46 jmespath-0.10.0 python-dateutil-2.8.2 s3transfer-0.5.0 six-1.16.0 urllib3-1.26.7 python-dotenv-0.19.0The two packages we installed are:
- boto3: This is the core Python AWS library we will be using in this guide
- dotenv: We will use this library to pass in sensitive information to it that we do not want to have hardcoded in our code such as the AWS credentials
Verifying it works
Now that we have setup our system we need to verify the library is installed properly and it works. You can do this by simply checking in a python shell using the following command shown below, if you encounter an error please delete your virtual environment and try again. If the problem still persists please drop me a line below and I will try to help you.
main ✚ (env) alex@DYNAMH ~/code/unbiased-coder/python-boto3-pagination-collections > python
Python 3.8.6 (default, Oct 23 2020, 14:59:35)
[GCC 9.3.0] on msys
Type "help", "copyright", "credits" or "license" for more information.
>>> import boto3
>>> boto3.__version__
'1.18.46'
>>> import dotenv
>>> quit()
As you can see above the boto3 library got loaded successfully and the version is 1.18.46. This is as of Late 2021 so this may be different in your system based on when you install it.
How to add an AWS user for Boto3 Pagination and Collections
Please refer to my AWS S3 guide on how to setup your AWS environment for S3 as we will be using the S3 service to test our paginators and Collections code. You can find the article here:
Boto3 S3 Upload, Download and List files (Python 3)
The link above will take you directly to the section on how to setup your environment with a step by step process.
What are the differences between Boto3 Pagination and Collections
| Pagination | Collections | |
|---|---|---|
| Programming style | More like an iterator | QuerySet like Django ORM |
| Ease of Use | Easy | Easy |
| Code clarity | Not good | Very clear and easy to read |
| Speed | Fast | Fast |
| Features | Poor | Rich |
How to use Boto3 pagination
Boto3 Pagination is an abstraction added by AWS in the Boto3 library to allow you to get information from sources on the AWS infrastructure that may be very long. Some examples of this can be:
- Long S3 bucket collections
- DynamoDB/RDS results
- Long list of EC2 instances
- Long list of Docker containers
And a lot of other similar things in nature. Today we are going to use S3 bucket collections with long listings in our examples and demonstrate how this works with Paginators.
How to Upload files to S3 folder Paginated
If we quickly glance as to how our S3 bucket looks we should see multiple files in our AWS web console.
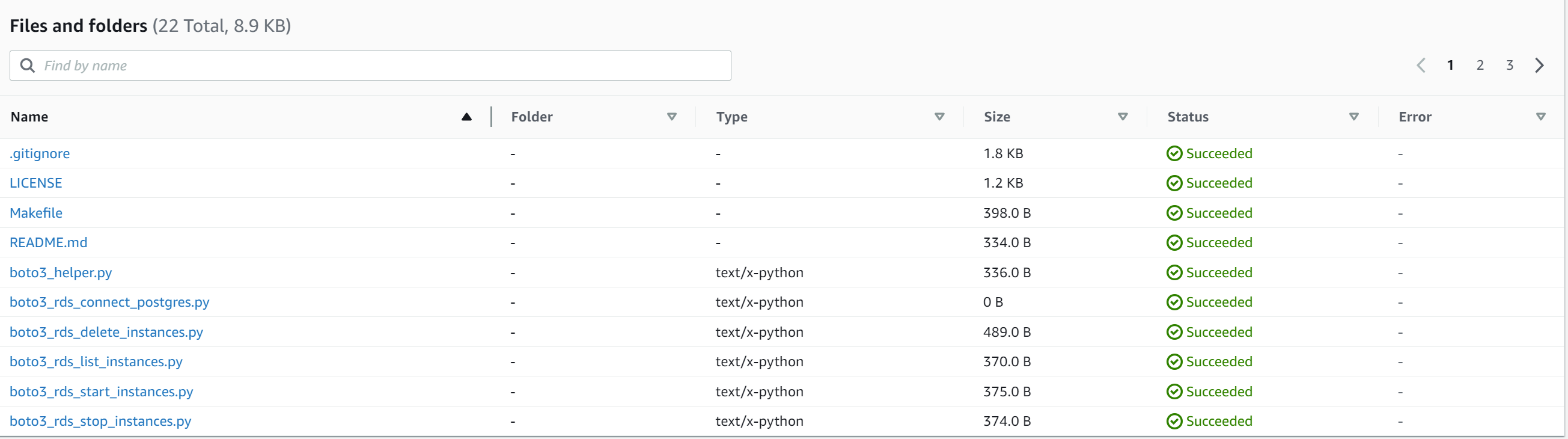
As you can see in the top right there’s 3 pages of pagination with the default view showing 10 files at a time. This can be adjusted to whatever page size you want but that’s the default that we will try to use in our examples below.
The sample bucket we will be using for this project and all of our examples is: s3://unbiased-coder-test-bucket. So any code references initializing the S3 library will be directly reading from this source.
Boto3 Pagination Example
The first thing we are going to demonstrate is how to do a simple pagination over a big result set that comes from the S3 bucket. For this we will leverage the boilerplate code for AWS that we described earlier in the S3 Article.
The initializer code sets up an AWS session which we are going to use as our channel to retrieve the data by parts.
import boto3_helper
def boto3_s3_list_files_using_pagination():
page_size = 3
session = boto3_helper.init_aws_session()
s3 = session.client('s3')
paginator = s3.get_paginator('list_objects')
page_iterator = paginator.paginate(Bucket='unbiased-coder-test-bucket', PaginationConfig={'PageSize': page_size})
print ('Fetching results using PAGE SIZE: ', page_size)
for page in page_iterator:
contents = page['Contents']
print ('Received number of results: ', len(contents))
for s3_obj in contents:
print (s3_obj['Key'])
boto3_s3_list_files_using_pagination()
The main take aways from the code above is that first we need to acquire a paginator object which basically gives us the results in a list and once this is done we can the go ahead and define our page size which is important as this is what separates the results in different API calls.
Making different API calls lets us get things by chunks and not overloading our system or running into memory problems. In the example above we set the Page size to 3 and then we execute with the output as it can be seen below.
main ● (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-pagination-collections > python3 ./boto3_pagination.py
Fetching results using PAGE SIZE: 3
Received number of results: 3
.gitignore
LICENSE
Makefile
Received number of results: 3
README.md
boto3_helper.py
boto3_rds_connect_postgres.py
...As expected we see chunks of 3 results at a time as we have defined our page size to 3. In this example we are simply printing out the object name rather than the entire object to keep the output clean. If you need more details you can simply avoid the ‘Key’ print out in the code and it will show you all the item results.
How to filter Boto3 Paginator
Now that we have demonstrated some basic usage for retrieving the results from our Paginator we are going to demonstrate how we can perform some basic filtering on the result set so we can select what we need and what we want to discard in our pagination list. The next step is to start adding some filters in the code to get less results from the remote end. This is abstracted in the code highlighted below. Do note the difference here is that we are using a client rather than a resource of the S3 to get access to that low level code.
import boto3_helper
def boto3_s3_list_files_using_pagination():
session = boto3_helper.init_aws_session()
s3 = session.client('s3')
paginator = s3.get_paginator('list_objects')
page_iterator = paginator.paginate(Bucket='unbiased-coder-test-bucket')
search_criteria = 'Contents[?Size > `500`][]'
filtered_iterator = page_iterator.search(search_criteria)
for s3_obj in filtered_iterator:
print ('File: ', s3_obj['Key'], 'with Size: ', s3_obj['Size'])
boto3_s3_list_files_using_pagination()How to find S3 files above a certain file size using pagination
In the example above we are filtering by file size of the S3 object. More specifically we are setting a condition to only give us back the results where the Size is greater to 500. The code below executes this.
main ● (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-pagination-collections > python3 ./boto3_pagination.py
File: .gitignore with Size: 1799
File: LICENSE with Size: 1211
File: boto3_session_mock.py with Size: 513
In our result set instead of returning all the objects we simply get back the 3 files on the S3 bucket that have size greater than 500. The second print out is the file size and the first one the name of it.
How to use Boto3 Collections
Collections is the newer welcoming addition to the AWS Boto3 library and aims to solve the same problem with a slightly different way of implementing it. We are going to use the same S3 bucket that we used in our previous example to demonstrate how collections work and how you can include them in your project.
The reasons for using a Boto3 Collection are identical to the AWS Boto3 Pagination as they both are geared into solving the same problem just using a different angle.
Boto3 Collections example
Similar to the Paginator example the first thing we are going to show is how to write some code that retrieves all the results without any filtering and how we can process them by parts without getting everything at once. We are going to follow the same paradigm which basically gives us a page size limit of 3 objects at time. The importance of this has been outlined earlier in the pagination example.
import sys
import boto3_helper
def boto3_s3_list_files_using_collections():
page_size = 3
session = boto3_helper.init_aws_session()
s3 = session.resource('s3')
bucket = s3.Bucket(name='unbiased-coder-test-bucket')
print ('Fetching results using PAGE SIZE: ', page_size)
for s3_file in bucket.objects.page_size(page_size):
print ('S3 file', s3_file)
sys.stdout.flush()
boto3_s3_list_files_using_collections()The difference in the code above is that we are seeing the code using a Django like syntax for the queryset and this allows us to simplify the code as much as possible. Since we are working with objects here we see the results in object format rather than a dictionary. However the same attributes are still accessible here as before.
main ● (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-pagination-collections > python3 ./boto3_collections.py
Fetching results using PAGE SIZE: 3
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-test-bucket', key='.gitignore')
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-test-bucket', key='LICENSE')
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-test-bucket', key='Makefile')
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-test-bucket', key='README.md')
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-test-bucket', key='boto3_helper.py')
....How to filter Boto3 Collections for file size
Now that we have all the results we wanted we will show how to take this a step further and start adding filtering conditions so we can narrow down our result set to only get things based on parameters we specify at the query level. Again we will follow the same example that we did earlier with paginators but this time with collections. As you may notice the code again looks simplified and much easier to read. In this case instead of pre-defining the filtering we do it on the fly at the object level.
import sys
import boto3_helper
def boto3_s3_list_files_using_collections():
session = boto3_helper.init_aws_session()
s3 = session.resource('s3')
bucket = s3.Bucket(name='unbiased-coder-test-bucket')
for s3_file in bucket.objects.all():
if s3_file.size > 500:
print ('S3 file', s3_file)
boto3_s3_list_files_using_collections()
How to find S3 files above a certain file size using collections
The one thing to notice again when we execute we are getting back objects rather than dictionaries and can be accessed in the same way as before. The result is similar to the previous pagination code that we executed and we get back those 3 file objects.
main ● (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-pagination-collections > python3 ./boto3_collections_filter.py
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-test-bucket', key='.gitignore')
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-test-bucket', key='LICENSE')
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-test-bucket', key='boto3_session_mock.py')Conclusion
If you found How to use Boto3 Pagination and Collections useful and you think it may have helped you please drop me a cheer below I would appreciate it.
If you have any questions, comments please post them below I check periodically and try to answer them in the priority they come in.
Also if you have any corrections please do let me know and I’ll update the article with new updates or mistakes I did.
Personally I like to use newer technologies and I’m a big fan of the Django ORM model approach for querysets so I’m naturally more inclined to gear towards using collections. However this is a matter of preference and what needs you have on your own design and implementation. Furthermore how the code reads to me is very important and I feel the queryset syntax reads out more naturally and it’s easier to have a clear picture of what it does with at a quick glance.
Which do you prefer Paginators or Collections?
If you would like to learn more about AWS Boto3 interfaces please take a look at the articles below:
- Boto3 DynamoDB query, scan, get, put, delete, update items
- Boto3 EC2 Create, Launch, Stop, List and Connect to instances
- Boto3 S3 Upload, Download and List files (Python 3)
- How to Setup an AWS Lambda Python Function From Scratch
- Boto3 Session: Setup Profile, Create, Close and Mock sessions
- Python Boto3 RDS: Postgres, MySQL, Connect, List, Start, Stop, Delete