
Introduction
Today I’m going to walk you through on how to use Boto3 S3 Upload, Download and List files (Python 3). We are going to do everything step by step starting from setting up your environment and any dependencies needed to getting a full working example. In the process I’m going to show you how this looks from the AWS console all the way to how the code can be adapted to be efficient. This simple task has small little tricks that you need to master when it comes to specifying paths and other limitations which we will demonstrate below and how you can address them to accomplish what you want.
I have been working in the Software industry for over 23 years now and I have been a software architect, manager, developer and engineer. I am a machine learning and crypto enthusiast with emphasis in security. I have experience in various industries such as entertainment, broadcasting, healthcare, security, education, retail and finance. I have been using AWS since inception and I’m familiar with all the technologies it has. My experience is not limited to the architecture but also doing a lot of hands on code and understanding the limits of each product AWS offers.
How to setup the environment for Boto3 S3
Before we start writing any code we will talk about how to setup the environment for Boto3 S3. We are going to begin on setting up our environment in particular installing any dependencies and packages necessary. I assume you already have Python 3 installed and running in your system. If you haven’t you can check the official website of Python to get that installed before proceeding forward. Furthermore I’m assuming you already have access to an AWS S3 account and own an SDK key. If you do not you can sign up for free with Amazon here to get started. I’m also making the assumption you have the Python Package manager pip. If you haven’t you can look into this guide to learn more about installing it.
Now that we have the basic requirements out of the way we can dive in and start setting up the system. Also I want to note that all of the code you will find in this guide can be found in Github here.
How to create a virtual environment for Boto3 S3
We need to go over the steps on how to create a virtual environment for Boto3 S3
- First install the virtual env using the python command: ‘pip install virtualenv’
- Then create a new virtual environment
- Finally you need to activate your virtual environment so we can start installing packages, please see below
main alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > virtualenv env
created virtual environment CPython3.8.6.final.0-64 in 3773ms
creator CPython3Posix(dest=/home/alex/code/unbiased-coder/python-boto3-s3-guide/env, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/home/alex/.local/share/virtualenv)
added seed packages: pip==21.2.4, setuptools==57.4.0, wheel==0.37.0
activators BashActivator,CShellActivator,FishActivator,PowerShellActivator,PythonActivator
main alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > source env/bin/activateHow to install pip dependencies for Boto3 S3
Next we need to go ahead and install the Python dependencies to be able to use the boto3 library. You can do this by running the pip tool as shown below. Keep in mind make sure your virtual environment is activated before you run this step. If you wish to use it without having a virtual environment which I do not recommend you can go ahead and simply install it globally in your user account.
main (env) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > pip install boto3 python-dotenv
Collecting boto3
Downloading boto3-1.18.46-py3-none-any.whl (131 kB)
|████████████████████████████████| 131 kB 1.1 MB/s
Collecting s3transfer<0.6.0,>=0.5.0
Downloading s3transfer-0.5.0-py3-none-any.whl (79 kB)
|████████████████████████████████| 79 kB 2.8 MB/s
Collecting botocore<1.22.0,>=1.21.46
Downloading botocore-1.21.46.tar.gz (8.2 MB)
|████████████████████████████████| 8.2 MB 11.5 MB/s
Collecting jmespath<1.0.0,>=0.7.1
Downloading jmespath-0.10.0-py2.py3-none-any.whl (24 kB)
Collecting python-dateutil<3.0.0,>=2.1
Downloading python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
|████████████████████████████████| 247 kB 10.1 MB/s
Collecting urllib3<1.27,>=1.25.4
Downloading urllib3-1.26.7-py2.py3-none-any.whl (138 kB)
|████████████████████████████████| 138 kB 9.9 MB/s
Collecting six>=1.5
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Building wheels for collected packages: botocore
Building wheel for botocore (setup.py) ... done
Created wheel for botocore: filename=botocore-1.21.46-py3-none-any.whl size=7933638 sha256=ee2d8a7f5bd91a7d2711b529706902a4a2a8fba97e69493757a8d1d461296d69
Stored in directory: /home/alex/.cache/pip/wheels/db/2a/b6/37624d07c0d7572bff3d08bd4bfd2c94b121f693278cd1ae77
Successfully built botocore
Collecting python-dotenv
Downloading python_dotenv-0.19.0-py2.py3-none-any.whl (17 kB)
Installing collected packages: six, urllib3, python-dateutil, jmespath, botocore, s3transfer, boto3, python-dotenv
Successfully installed boto3-1.18.46 botocore-1.21.46 jmespath-0.10.0 python-dateutil-2.8.2 s3transfer-0.5.0 six-1.16.0 urllib3-1.26.7 python-dotenv-0.19.0The two packages we installed are:
- boto3: This is the core Python AWS library we will be using in this guide
- dotenv: We will use this library to pass in sensitive information to it that we do not want to have hardcoded in our code such as the AWS credentials
Note that dotenv is optional and may not be needed for your needs. You can also store the environment variables inside your Python file or hosted in AWS using the kms service.
I also have a full example of using the session as is on it’s own which you can find here:
Verifying it works
Now that we have setup our system we need to verify the library is installed properly and it works. You can do this by simply checking in a python shell using the following command shown below, if you encounter an error please delete your virtual environment and try again. If the problem still persists please drop me a line below and I will try to help you.
main ✚ (env) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > python
Python 3.8.6 (default, Oct 23 2020, 14:59:35)
[GCC 9.3.0] on msys
Type "help", "copyright", "credits" or "license" for more information.
>>> import boto3
>>> boto3.__version__
'1.18.46'
>>> import dotenv
>>> quit()
As you can see above the boto3 library got loaded successfully and the version is 1.18.46. This is as of Late 2021 so this may be different in your system based on when you install it.
How to create an AWS S3 bucket Using Web Console
To create a new AWS S3 bucket you need to login to your Amazon AWS account and navigate to the AWS S3 bucket page found here. Note this will take you automatically to us-east-1 region which is the default location for me as I’m located in the US so if you want to adjust the region please click on the top right and change it to whatever you want. The landing page for S3 should look something like this when it’s bare.
The first thing we need to do is click on create bucket and just fill in the details as shown below. For now these options are not very important we just want to get started and programmatically interact with our setup.
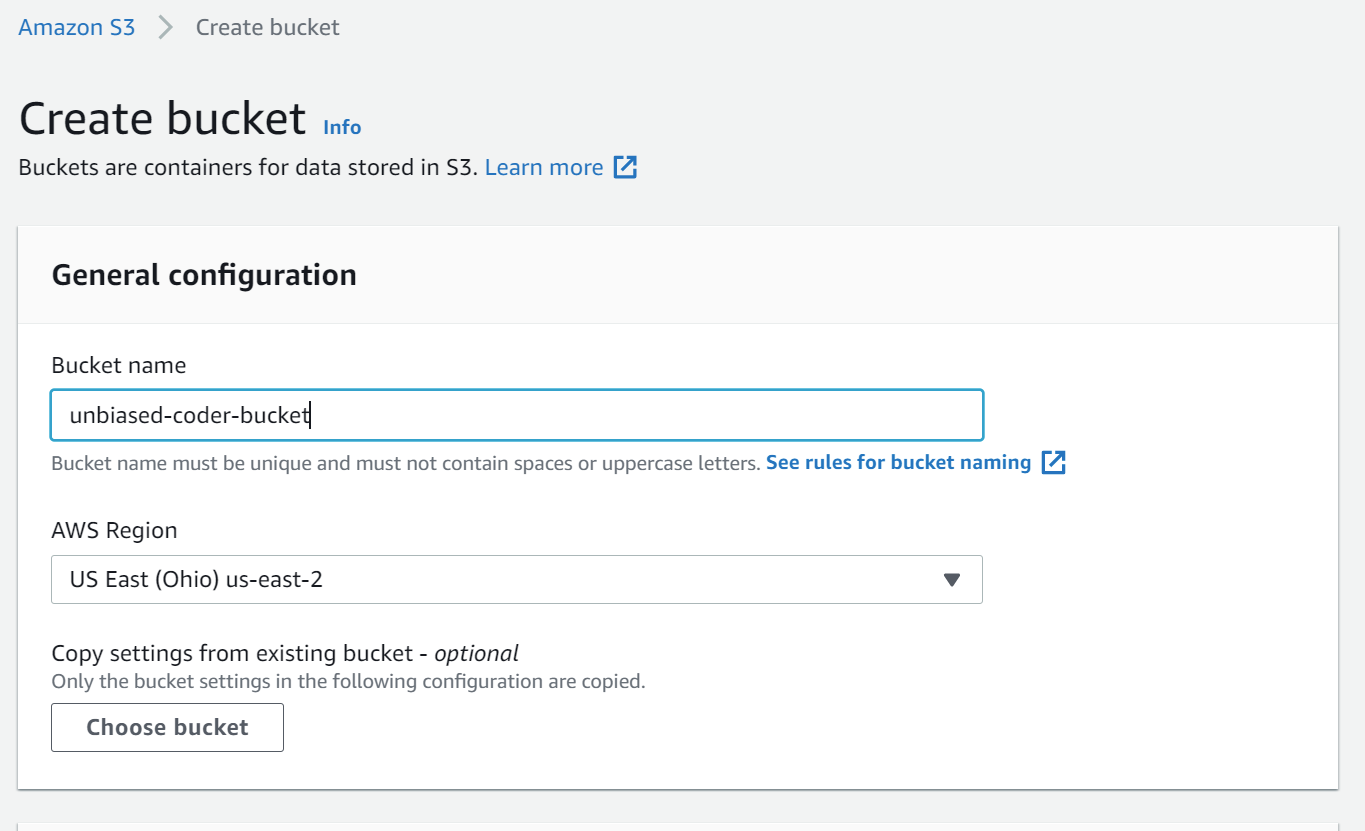
For now you can leave the rest of the options default for example for me the following settings were default at the time of this writing:
- Encryption: OFF (you can turn this on but not needed)
- Block all public access
- Bucket versioning: OFF (you can turn this on but not needed)
- Tags: empty (you can add some if you wish too)
- Object lock: disable
Once you verify that go ahead and create your first bucket. For me this looks something like this:

How to setup AWS Keys
Now that we have our bucket created we need to proceed further into setting up a way to interact with it programmatically. In order to do this Amazon AWS uses something called SDK keys. Those are necessary for the platform to know you are authorized to perform actions in a programmatic way rather than logging in the web interface and accessing the features via the console. So our next task is to find where and how those keys are configured and what is needed to set them up on our local computer to start talking to Amazon AWS S3.
How to add an AWS user For S3 Permissions
First we need to talk about how to add an AWS user. If you do not have a user setup with AWS S3 full permissions then I will walk you through on how to get this done in a simple step by step guide. The first thing you need to do is head over to the IAM page on AWS console and click on creating a new user.
In the next steps you can use the defaults except the part that is asking you to set the permissions. In this tab you want to expand below and type in the search S3. Once you do that a bunch of permissions will be loaded for you to select from, for now you can simply select the Full permissions for S3 as shown in the screenshot below.
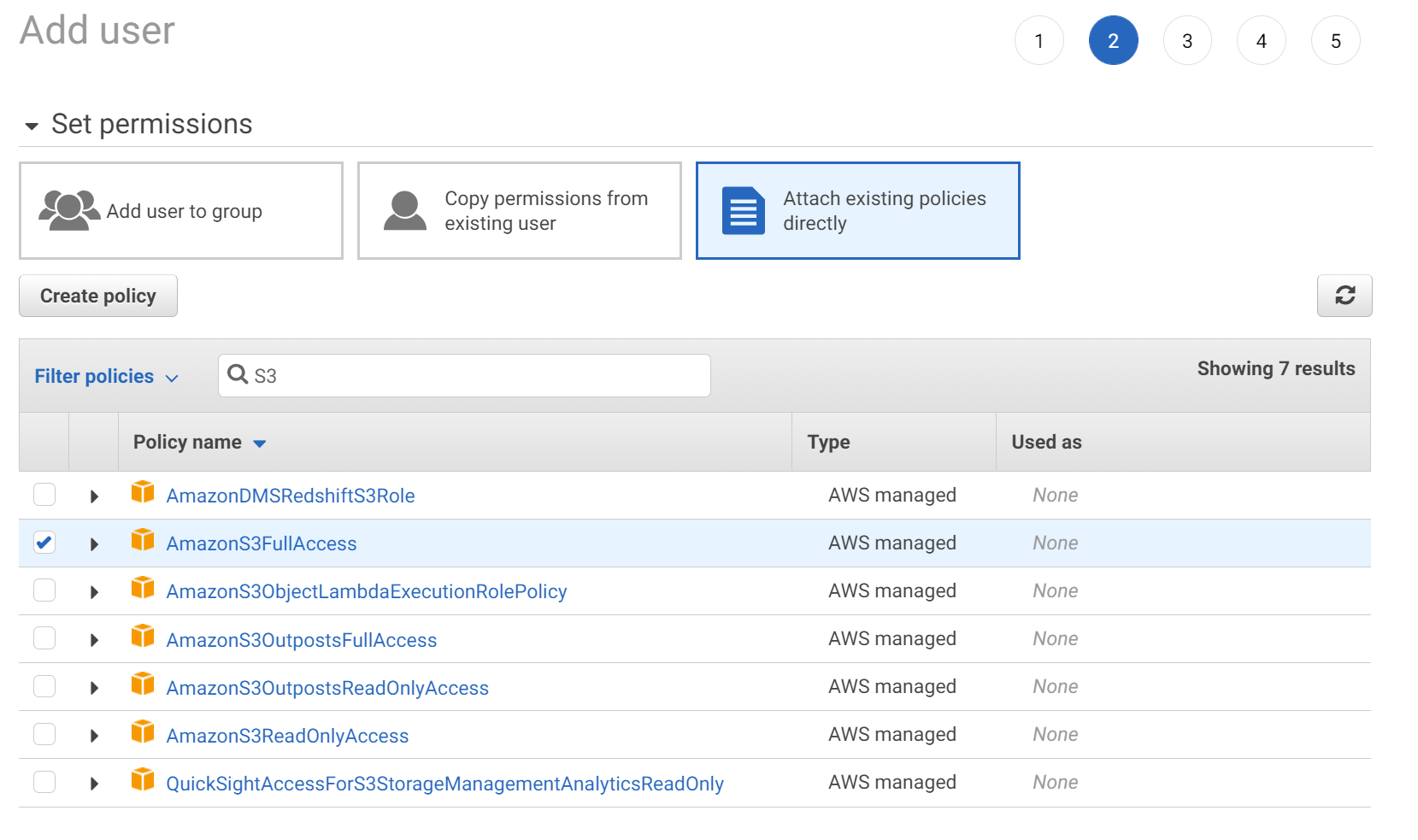
You can skip the tags and proceed to add the user, the final screen summary should look like this.
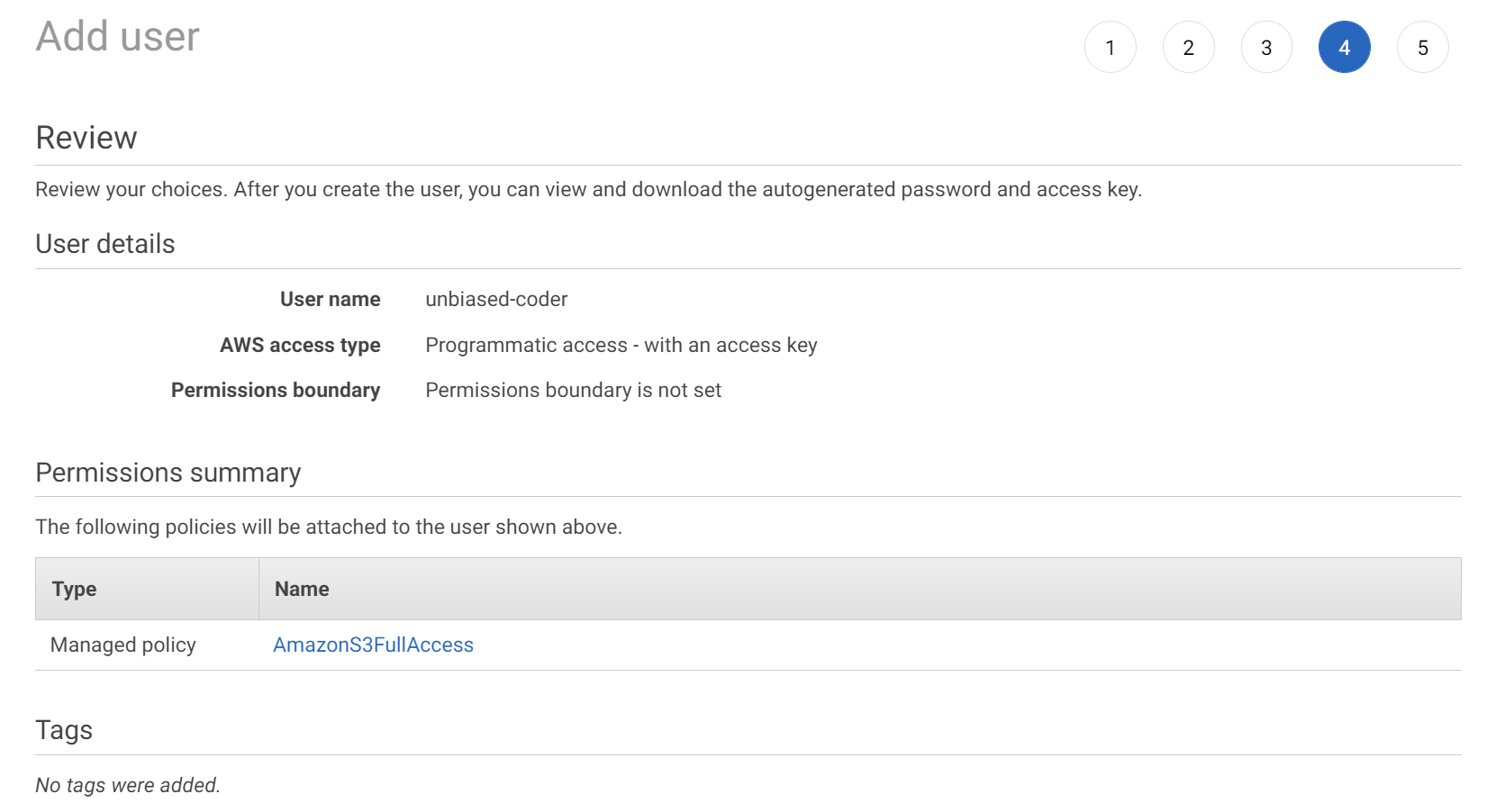
The final confirmation screen should show you the access key and the secret key. You want to save those for your reference as we would be using them in our code later. This screen looks something like this:
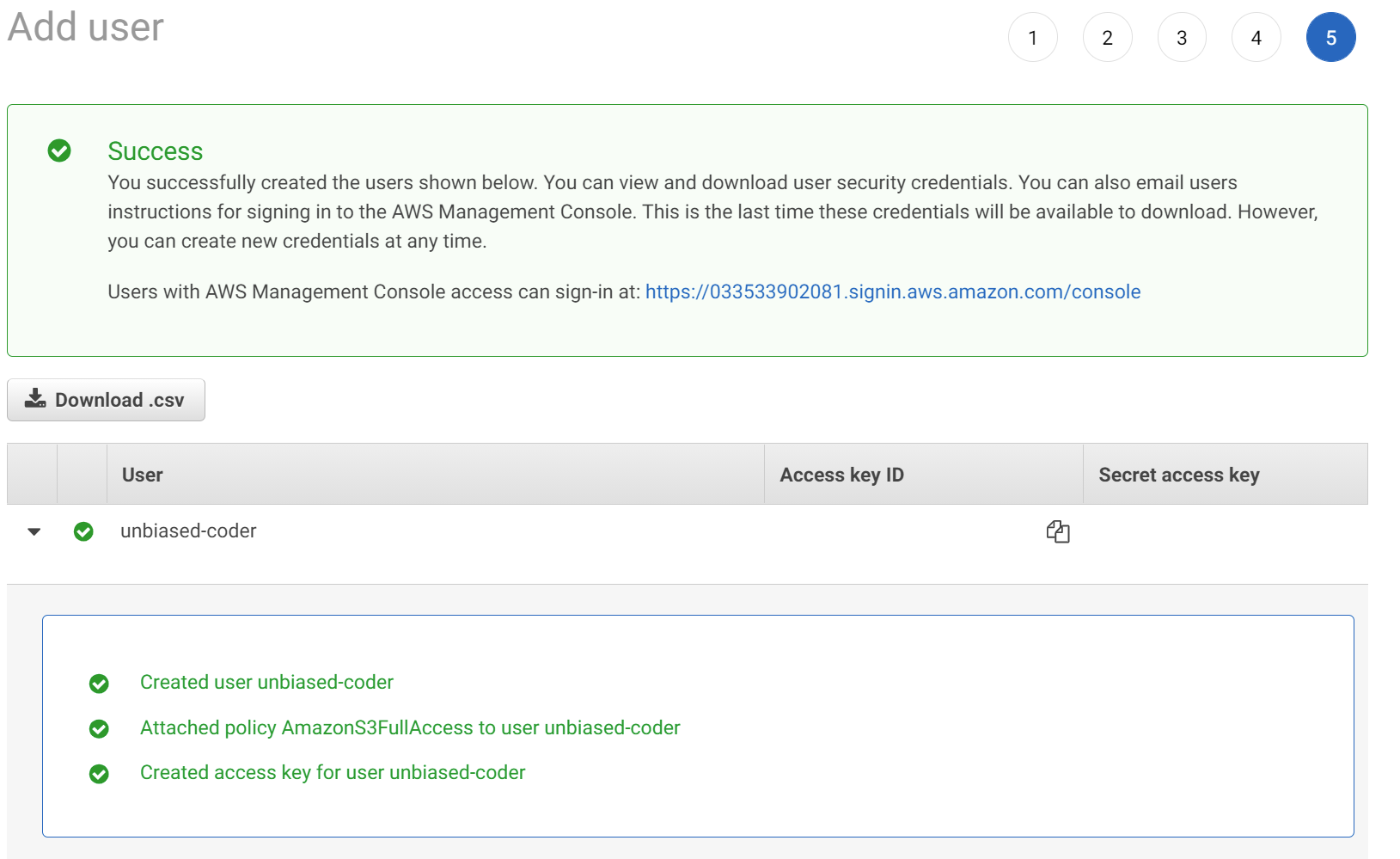
Do note I redacted my access and secret key from the screenshot for obvious reasons but you should have them if everything worked successfully.
How to create an Access and Secret Key For AWS S3
One more step we need to do before we start coding how Boto3 S3 Upload, Download and List files (Python 3) is to create an AWS API and secret key setup in our system. Now that we have an access and secret key and our environment setup we can start writing some code. Before we jump into writing code that downloads uploads and lists files from our AWS bucket we need to write a simple wrapper that will be re-used across our applications that does some boiler plate code for the boto3 library.
One thing to understand here is that AWS uses sessions. Similar to when you login to the web console a session is initiated with a cookie and everything in a similar way this can be done programmatically. So the first thing we need to do before we start accessing any resource in our AWS environment is to start and setup our session. In order to do that we will leverage the library we installed earlier called dotenv. The reason we will use this is to access our secret and access key from the environment file. We use an environment file for security reasons such as avoiding to hardcode any values in our code base.
The environment file basically tells Python that the data will live in the process environment which is in memory and does not touch any source file. In a way this is similar to setting environment variables in your terminal but for convenience we set them in our .env file. The format of this would look something like this:
AWS_S3_ACCESS_KEY=AKIAQXXXXXXXXXFV6YYY
AWS_S3_SECRET_KEY=fbhjkh43fjdkjkfdfdjk3jkMZmdsU1The data values above have been randomized for obvious reasons. But as you can see we are setting two variables here one for our access and one for our secret key which our code will be reading from in order to use them to initialize our AWS session. If we take a look at the boiler plate code it’s pretty simple and as described above it basically gives us an AWS session object to use later. This can be seen in the code below:
import os
import boto3
from dotenv import load_dotenv
def get_aws_keys():
load_dotenv()
return os.getenv('AWS_S3_ACCESS_KEY'), os.getenv('AWS_S3_SECRET_KEY')
def init_aws_session():
access_key, secret_key = get_aws_keys()
return boto3.Session(aws_access_key_id=access_key, aws_secret_access_key=secret_key)How to upload a file using Boto3 S3
Now that we have our keys setup we will talk about how to upload a file using Boto3 S3. We will start by uploading a local file to our S3 bucket. The code we will be writing and executing will leverage the boto3 helper python code we wrote above. As a reminder you can find all of that code in the GIT repo if you still haven’t checked it out you can find it here. The steps to accomplish this are the following:
- Initialize our S3 session with the helper code above
- Get an S3 resource (not client). As a summary a resource is basically a higher level interface than a client. The client uses the low level APIs that AWS understands since Amazon has created a resource for S3 we will leverage it here and make use of it.
- Once we initialize the S3 resource we will then want to go ahead and call the upload functionality it has to send our file to the S3 bucket.
All of this can be seen in the code below:
import boto3_helper
def boto3_s3_upload_file(filename):
print ('Uploading file: %s to bucket: unbiased-coder-bucket... '%filename, end='')
session = boto3_helper.init_aws_session()
s3 = session.resource('s3')
s3.meta.client.upload_file(filename, 'unbiased-coder-bucket', filename)
print ('done')
boto3_s3_upload_file('test.txt')
boto3_s3_upload_file('test1.txt')
One thing to note here is that we are uploading 2 files test.txt and test1.txt to our unbiased-coder-bucket. This assumes you have created the files locally (if not you can use the ones from the git repo) and you need to have created a bucket as it was shown earlier called unbiased-coder-bucket. If you choose a different name just replace the code above accordingly with the bucket name you chose to use.
Since some of you have asked me what the end=” does in the print statement this is simply a trick to tell the print function not to add a new line at the end of the print out and terminate with nothing. If we were to execute the code above you would see it in the output:
main ●✚ (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > python ./boto3_s3_upload_file.py
Uploading file: test.txt to bucket: unbiased-coder-bucket... done
Uploading file: test1.txt to bucket: unbiased-coder-bucket... doneThis shows that we successfully uploaded two files in our S3 bucket in AWS. To verify that everything worked for now we can login to the AWS console and see if the files are there. Later in the article we will demonstrate how to do this programmatically. If you were to login to the AWS console you will see something like this:

As you can tell both of our files were uploaded successfully into AWS.
If you wanted to create a directory or put them in a directory inside the AWS folder then you would have to add the prefix in the last argument of the upload_file function, so that would look something like this:
s3.meta.client.upload_file(filename, 'unbiased-coder-bucket', 'prefix-dir/'+ filename)In the above scenario basically the file will be uploaded into the prefix-dir from the root of our unbiased-coder-bucket.
AWS S3 Multipart Upload
A variation of what we did earlier is the AWS S3 multipart upload using boto3. Basically the idea here that your file is too big to be uploaded in one shot and may reach a lambda timeout if you are executing other commands too.
The solution to this is to use AWS S3 multipart upload which lets you break up the file in small pieces and then upload it to the AWS S3 bucket. Lets take a closer look at how some sample code of this would look.
Again you need to make use of the initializer code to setup your AWS S3 session but then it’s as simple as using the python seek command to get parts of your file descriptor and send it to AWS S3 using Boto3.
Example code of AWS S3 Multipart upload:
s3 = boto3.client('s3')
bucket_name = 'unbiased-coder-bucket'
file_name = 'large_file_to_be_uploaded.bin'
response = s3.create_multipart_upload(Bucket=bucket_name, Key=file_name)
upload_id = response['UploadId']
# what chunk size we want to use for our upload
part_size = 10 * 1024 * 1024
# we will be starting at 0 offset in our file (this may be passed along in other lambdas)
start_offset = 0
part_number = 1
with open(file_name, 'rb') as file:
while file_position < os.path.getsize(file_name):
file.seek(file_position)
data = file.read(start_offset)
response = s3.upload_part(Bucket=bucket_name, Key=file_name, UploadId=upload_id, PartNumber=part_number, Body=data)
start_offset += len(data)
part_number += 1
response = s3.complete_multipart_upload(Bucket=bucket_name, Key=file_name, UploadId=upload_id)
print ('Received response from AWS S3: ', response)
In the example above we make some observations:
- The response that comes back is basically what tells us where to continue if it’s successful or not
- We are storing the offset at all executions so you may need to pass this in the next event call of your lambda or store it in a queue somewhere so the next execution knows where to resume
- The key function that does the multipart upload is basically complete_multipart_upload
The code above may come in handy in other situations too where you want to do a multithreaded upload of your file and the conditions depend on your chunks. Just remember that you may have to reconstruct the file once you retrieve it again from AWS S3. For example implementations such as torrent use chunks of files to be downloaded but it can be in any implementation.
How to Download a file using Boto3 S3
In this section we will go over on how to download a file using Boto3 S3, similar to uploading a file to S3 we will implement the download functionality:
- Initialize our S3 session
- Get an S3 resource (similar to what we did above).
- Once we initialize the S3 resource we will then want to go ahead and call the download functionality it has to get our file from the S3 bucket.
All of this can be seen in the code below:
import boto3_helper
def boto3_s3_download_file(filename):
print ('Downloading file: %s to bucket: unbiased-coder-bucket... '%filename, end='')
session = boto3_helper.init_aws_session()
s3 = session.resource('s3')
s3.meta.client.download_file('unbiased-coder-bucket', filename, filename + '.new')
print ('done')
boto3_s3_download_file('test.txt')
boto3_s3_download_file('test1.txt')
The code above will download from our bucket the previously two files we uploaded to it. But you will ask won’t that overwrite the existing files that we have in our folder? The answer is no because the last argument of the download file is the destination path. As you can see above we are appending the ‘.new’ extension at the end of the file so the downloaded files should look like test.txt.new and test1.txt.new. Lets demonstrate the execution of this example:
main ●✚ (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > python ./boto3_s3_download_file.py
Downloading file: test.txt to bucket: unbiased-coder-bucket... done
Downloading file: test1.txt to bucket: unbiased-coder-bucket... done
main ●✚ (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > ls -al *.new
-rw-r--r-- 1 alex None 67 Sep 23 00:16 test.txt.new
-rw-r--r-- 1 alex None 75 Sep 23 00:16 test1.txt.new
As it can be seen above the files where successfully downloaded locally on our machine.
How to list files in Bucket using Boto3 S3
Next we will discuss on how to list files using Boto3 S3 from our bucket. This is particularly useful when scripting code as a batch job that runs periodically and also acts as a verification that your data is there when it should be. I personally always use the listing function to verify that some of my backup’s and image collections are there intact but everyone could have a different use case for this functionality.
The steps involved to write this code is slightly different that the two previous ones (download/upload file).
- As a first step we need to get an AWS session as before
- Then we need to acquire again an S3 resource
- Once we have this we need to do a couple of more things:
- Acquire a bucket object, this is basically a programmatic mapping of our S3 bucket folder which has various properties such as listing items etc. You can think of it as a collection of items that you can iterate from.
- Using this object use the iterator to get all items inside the bucket we have provided it with.
The code that implements how to list files in bucket:
import boto3_helper
def boto3_s3_list_files():
session = boto3_helper.init_aws_session()
s3 = session.resource('s3')
bucket = s3.Bucket(name="unbiased-coder-bucket")
for s3_file in bucket.objects.all():
print (s3_file)
boto3_s3_list_files()
The code example above is basically listing files but for boto3 list objects it’s the naming convenience AWS uses to include more attributes and tags associated with it.
Lets take a look at another example in this case we will be using boto3 list objects and from those objects we will filter by tag:
objects = s3.list_objects_v2(
Bucket=bucket_name,
TagFilters=[
{
'Key': MY_KEY,
'Value': MY_TAG
}
]
)
As you can see above the difference here is in boto3 list objects using v2 which essentially lets us apply a filter with the TagFilters key parameter. We can also perform this operation in boto3 list objects using a simple for loop but then you are driving most of the CPU work in our client. Below I will explain how to list objects using that approach.
In the instance above we are not applying any filters on the objects we are requesting but we can easily do that if we wanted too. For example lets say we had a folder in our bucket called sub-folder and wanted to list all the items in it we would be adjusting the code to look like this:
for s3_file in bucket.objects.filter(Prefix='sub-folder/'):The filtering is pretty handy especially if you are using boto3 to list files in bucket with a large directory. You could perform operations such as applying directory listings on file types and easily get visibility in those files. Additionally this is very similar to a file system but the difference is that here we are using boto3 list objects which is essentially a file with additional metadata.
In our case since we do not have a sub-folder directory it will not return any results if we were to execute the new code. One common question that I always get is:
How do you use wildcards in boto3 s3
And the answer is you simply can’t do that unless you use the command line. However you can always request all the files in a directory and then using python you can check the extension of the file and see if it matches what you are looking for. So for example a simple if condition would do that. Let’s take a look at some code that only lists .txt files for us, the adjusted code is:
for s3_file in bucket.objects.all():
if (s3_file.key.lower().endswith('.txt')):
print ('S3 file', s3_file)
If we were to execute the code above and there were multiple files in our folder with different extensions, we would only be printing/processing the files ending with .txt.
How to delete files using Boto3 S3
Finally we will talk about how to delete files using Boto3 S3. Since we have covered most of the aspects on using Boto3 alongside with S3 lets cover the last part which is deleting files from your bucket folder. The difference between listing and deleting is actually very minor in the code. The idea is you still follow similar steps on getting an object and based on the object or list of objects you can issue the delete operation. More specifically:
- We follow the similar steps that we just discussed about listing files but further once we acquire an object or an object list
- We issue the delete command on that set of objects.
An example of this code is the following:
import boto3_helper
def boto3_s3_delete_files():
session = boto3_helper.init_aws_session()
s3 = session.resource('s3')
bucket = s3.Bucket(name="unbiased-coder-bucket")
print("Deleting all files in bucket")
bucket.objects.all().delete()
boto3_s3_delete_files()In the example above we are deleting everything as showing in bucket.objects.all().delete() if we were to use a filter and acquire an object per file we can also issue the delete command specifically on the files we want to delete. Now that we finished writing our code lets go ahead and test it.
main (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > python ./boto3_s3_list_files.py
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-bucket', key='test.txt')
S3 file s3.ObjectSummary(bucket_name='unbiased-coder-bucket', key='test1.txt')
main (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > python ./boto3_s3_delete_file.py
Deleting all files in bucket
main (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide > python ./boto3_s3_list_files.py
main (venv) alex@DYNAMH ~/code/unbiased-coder/python-boto3-s3-guide >As it can be seen above in the first run where we list our files you can see there’s two files in the folder: test.txt and test1.txt. After we issue the delete command those files are gone. To ensure this worked we re-issue the command of listing the files and it returns no results. If you are still not convinced you can check on the web console to see if the bucket is empty.
Conclusion
Overall I’m a big fan of doing things programmatically when it comes to AWS and I believe Amazon has provided a great library with a lot of flexibility but it does have it’s limitations as demonstrated above. The bigger problem here is that we need to be aware of those and be adaptable after all nothing in life is perfect!
If you found my article on Boto3 S3 Upload, Download and List files (Python 3) useful please drop me a cheer below I would appreciate it.
If you have any questions, comments below I check periodically and try to answer them in the priority they come in.
Also if you have any corrections please do let me know and I’ll update the article with new updates or mistakes I did.
Which AWS service do you use programmatically?
I have some other articles similar to this on how to manage EC2 and Lambdas: